 PART04.2장 R 프로그래밍 기초(함수)
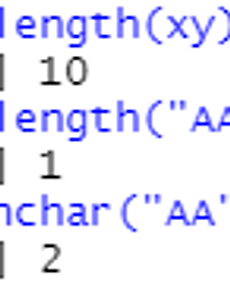
PART04.2장 R 프로그래밍 기초(함수) APPLY apply는 데이터 자료구조에서 row, column 단위로 계산을 적용하기 위한 함수 apply(자료구조, 행/열 별(1, 2), 적용 함수) lapply : lapply(data, function) 결과를 리스트로 반환 ( 열 단위) sapply : sapply(data, function) 결과를 벡터, 행렬로 반환(열 단위) tapply : tapply(data, index, function) data를 index에 입력된 분류별로 function 적용, sql의 group by와 유사 LENGTH VS NCHAR x
2022. 6. 3.
PART04.2장 R 프로그래밍 기초(함수)
PART04.2장 R 프로그래밍 기초(함수) APPLY apply는 데이터 자료구조에서 row, column 단위로 계산을 적용하기 위한 함수 apply(자료구조, 행/열 별(1, 2), 적용 함수) lapply : lapply(data, function) 결과를 리스트로 반환 ( 열 단위) sapply : sapply(data, function) 결과를 벡터, 행렬로 반환(열 단위) tapply : tapply(data, index, function) data를 index에 입력된 분류별로 function 적용, sql의 group by와 유사 LENGTH VS NCHAR x
2022. 6. 3.
 PART04.2장 R 프로그래밍 기초(그래픽기능)
PART04.2장 R 프로그래밍 기초(그래픽 기능) 산점도 그래프 x에 대한 y의 그래프 : plot(x, y), plot(y~x) height=c(170,160,165,190,120) weight=c(70,100,89,55,66) plot(height, weight) 산점도 행렬 pairs(iris[1:4], main="andre", pch=21, bg=c("red", "green","blue")[unclass(iris$Species)]) 히스토그램과 상자 그림 StatScore=c(1:50, 3) hist(StatScore) # 히스토그램 boxplot(StatScore) # 상자그림 hist(StatScore, prob=T) # 히스토그램, 상대도수 표시
2022. 6. 3.
PART04.2장 R 프로그래밍 기초(그래픽기능)
PART04.2장 R 프로그래밍 기초(그래픽 기능) 산점도 그래프 x에 대한 y의 그래프 : plot(x, y), plot(y~x) height=c(170,160,165,190,120) weight=c(70,100,89,55,66) plot(height, weight) 산점도 행렬 pairs(iris[1:4], main="andre", pch=21, bg=c("red", "green","blue")[unclass(iris$Species)]) 히스토그램과 상자 그림 StatScore=c(1:50, 3) hist(StatScore) # 히스토그램 boxplot(StatScore) # 상자그림 hist(StatScore, prob=T) # 히스토그램, 상대도수 표시
2022. 6. 3.



